This is a small update on an experiment with context ingestion that is in early-ish stage development.
ZymeDB, as we’ve been calling it internally, is a context management layer tuned for creative businesses like studios and agencies. This post describes a bit of its design, but also reflects on some emergent cultural reasons to be building something like this right now.
The atmosphere around AI adoption has undergone a slow but steady sea change in recent months. The perspective adjustment is mainly around AI as an orchestrator of meaningful input, as opposed to a producer of meaningful output.
Language models are only as capable as the context you provide for them. As harnesses get refined, context windows grow, and open source models become more capable, the focus has shifted toward sophisticated ingestion software and context management systems.
In the business realm, these are now called “Memory Systems” - tools like Honcho and Mem0, designed for teams that need to be contextually aligned around shared data.
The concerning side of this shift is the rhetoric around businesses and their “intelligence layers,” and what that implies for privacy. Jack Dorsey recently made an appearance on a podcast called Long Strange Trip, created by…Sequoia Capital, in which he postulates:
Like look at all the information you’re generating just by doing your work. Like just putting that into an intelligence and being able to query it will give you an understanding of the company that like is two to three times more than you had before ever. Because you’re relying upon people telling you things and you know that doesn’t always happen for various reasons…imagine if your company was entirely legible, like entirely legible, every aspect of it, and we’re not far off from that from a data perspective.
It’s not a leap to assume large organizations would prefer to hoover up every Slack message into a company context layer to build a central intelligence in the name of “radical transparency.” Beyond the privacy concerns, this also sets a precedent for self-censorship (or poisoning), and therefore bad signal, undermining the whole effort.
Our perspective is that context management should be more like auto-fiction and less like a court record. It can wear different masks, play with its identity, be in constant flux, and always opt-in.
There’s some friction in being required to manually contribute (or in toggling on auto-contribution by choice), but that friction is the point. It encourages a sense of personal ownership over the context, and the context is made richer by intent.
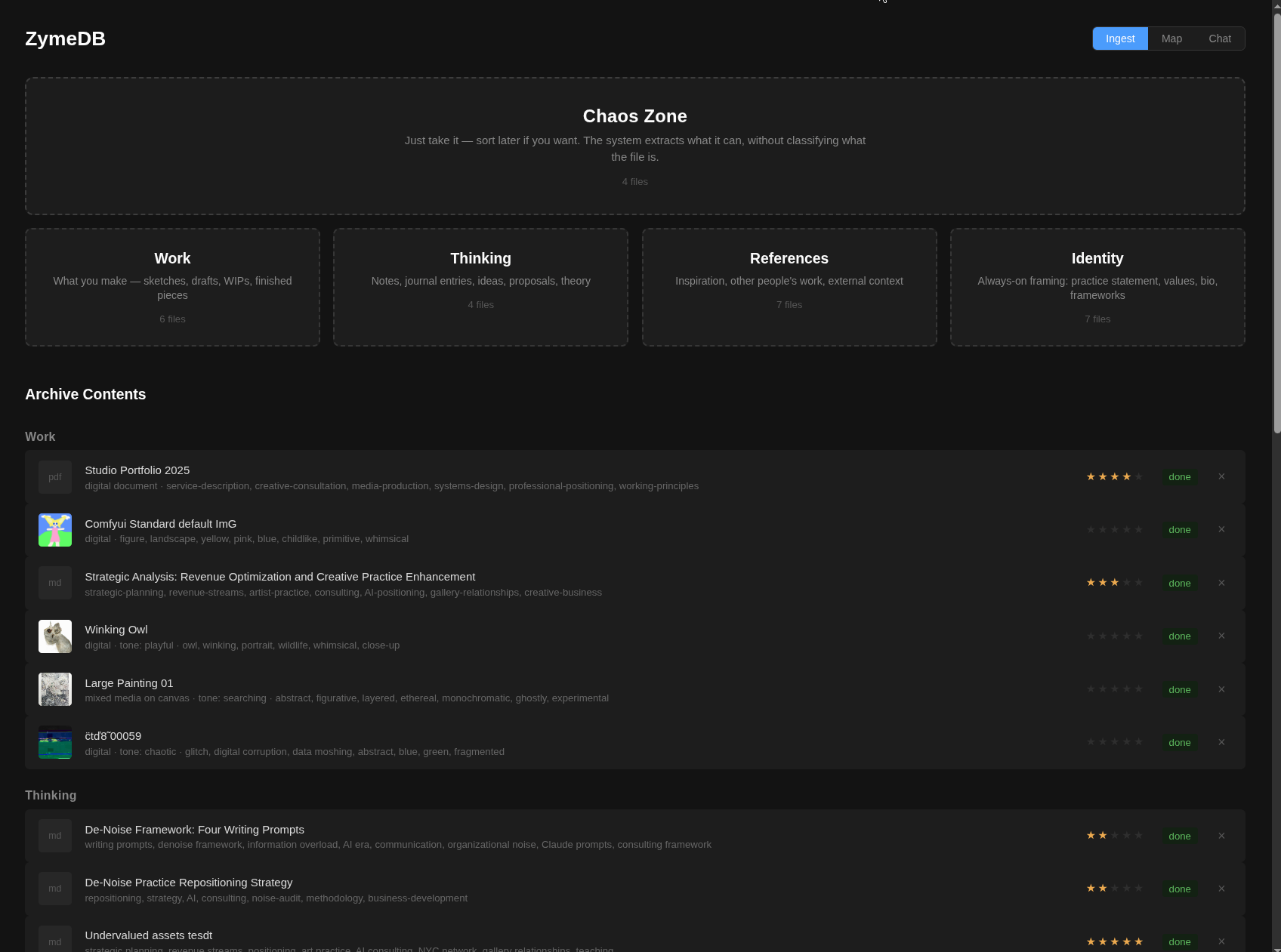
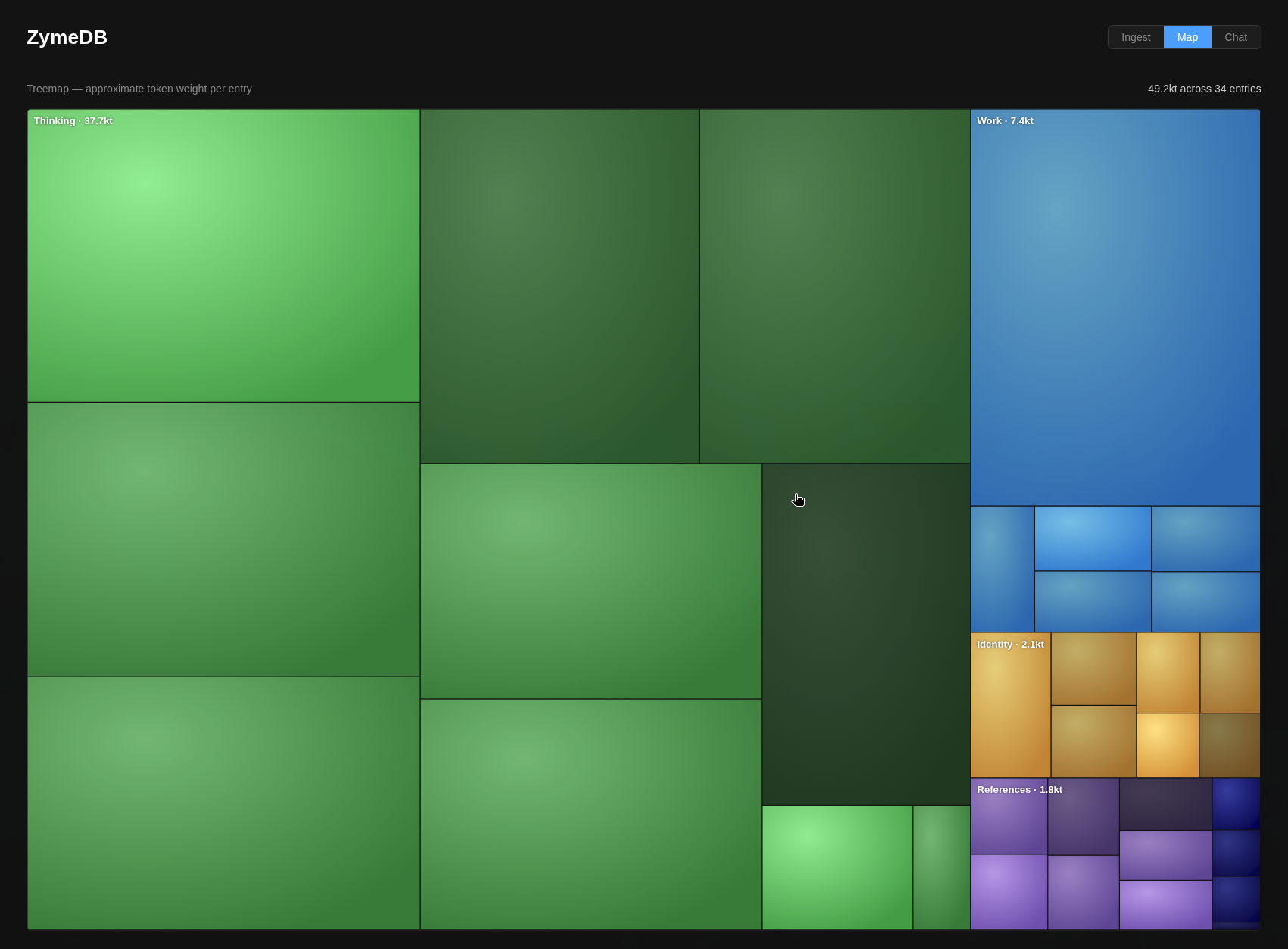
A few key features/philosophies of ZymeDB:
Platform agnostic and self-hosted. Take it with you. Own the whole layer, rather than having it obfuscated behind enterprise opinions that prioritize vendor lock-in.
Functional for any organizational style. Some people prefer meaningful chaos. Others like to tag everything perfectly and trim the hedges.
Built principally for creative production. Categories, skills, and tooling layers designed for how creative businesses think about their work.
Forkable, moddable, made to spec. Software is more liquid than it’s ever been. Values and taste are what make it durable.
More posts as development progresses. In the meantime, if you’re interested in trying it out or want more on the design, send us an email at contact@zymeresearch.com.